
*
So the World Cup is over, Germany are fitting champions, Lionel Messi couldn’t add the ultimate title to his glittering CV and the host nation is left to ponder what might have been. So who could have forecast this? Actually, a huge variety of ‘experts’, theorists, modelers and systems tried to predict the outcome of the tournament, from Goldman Sachs to boffin statistical organisations. In his latest post for Sportingintelligence, and as a wrap-up of an ongoing evaluation of rates of success (click HERE for Part 1 and background and click HERE for Part 2 and HERE for Part 3) Roger Pielke Jr announces the winners and losers from the forecasting game.
Follow Roger on Twitter: @RogerPielkeJR and on his blog
.
 By Roger Pielke Jr.
By Roger Pielke Jr.
16 July 2014
Another World Cup is now history, and with it my World Cup prediction evaluation exercise. As a reminder, this exercise is based on rankings made before the tournament started with the details of the evaluation explained here.
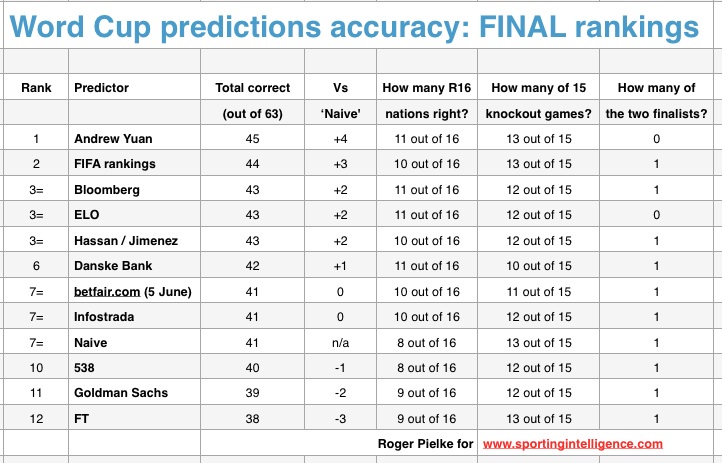
So to the results. Overall, Andrew Yuan, whose predictions were popularised by The Economist, took first place, beating FIFA’s rankings by a single match. Of course, it is no surprise those two were so close as Yuan and the FIFA rankings had 60 of 63 identical match predictions.
After FIFA there is a three-way tie for the bronze medal, with Bloomberg, Elo rankings and Hassan and Jimenez sharing the third step of the podium. Of note is that the latter was produced four months ago, well before the national team rosters were even announced.
The full table is as follows, and article continues below:
.
One of the leaders after the group stage of the tournament, Danske Bank, performed the worst in the knockout portion of the World Cup, and slipped from the podium. By contrast, the worst performer during the group stage (Financial Times) was joint first during the knockout matches. With these methods, past performance is apparently not a good predictor of future performance.
None of the other methods outperformed the naive baseline based on TransferMarkt player values that I assembled prior to the tournament. Three methods actually under-performed that naive baseline. Were you to pick one of these methods (other than FIFA or Transfermarkt) at random prior to the tournament, you would have had a 10 per cent chance of beating FIFA and a 50 per cent chance of beating Transfermarkt.
The table above also shows how each method performed in the knockout portion of the tournament, in anticipating advancement from the group stage, and in anticipating the finalists. Interestingly, the overall winner was only one of two methods which failed to anticipate one of the finalists.
No method anticipated both Germany and Argentina in the final, and no method picked Germany to win it all. This website’s editor considered other models to predict the winner before the tournament, and made a personal forecast of an Argentina-Germany final, but he picked the wrong winner.
Here are some more general lessons to take from prediction exercise:
1: Prediction evaluation is highly sensitive to the methodology employed. For instance, were the evaluation method to award a three-game “bonus” to any method than anticipated a finalist, Andrew Yuan would fall from first place to sixth place. The weighting of results can consequently dramatically change the evaluation rankings.
In any prediction evaluation it is therefore important to settle upon an evaluation methodology in advance of the data actually coming in. It is also important to keep separate the roles of predictor and evaluator. It is obviously very easy to “game” an evaluation to look more favorable to a particular prediction method, simply by choosing a convenient evaluation metric. Be cautious with anyone who offers you both a prediction and an evaluation of their prediction, especially after the fact.
2: Beating a simple baseline is very difficult. We might debate how “naive” the FIFA rankings or Transfermarkt valuations actually are in practice. But both clearly outperformed more sophisticated approaches. The only method which actually out performed FIFA was one which successfully picked two of the three matches that they had different across the entire tournament. Was that luck or skill? None of the other 10 methods added any value beyond the FIFA rankings. Should they have even bothered?
Even though outperforming a naive baseline over a tournament is difficult, that does not take away for the entertainment value of predictions. For instance, FiveThirtyEight performed poorly according to the evaluation methods here, but nonetheless offered stimulating commentary throughout the tournament, in part based in its predictions.
3: Ultimately, we can never know with certainty how good a predictive methodology actually is in practice. Some systems that we wish to predict have closed boundaries, such as a deck of 52 cards. We can develop probabilistic predictions of poker hands with great certainty. In the real world, we can sometimes (but not often) accumulate enough experience to generate predictions of open systems that also have great certainty, like the daily weather forecast.
But other systems are not subject to repeated predictions and/or are so open as to defeat efforts to bound them. The World Cup, and sporting events in generally, typically fall into these categories. Arguably, so too does much of the human experience. Perhaps baseball, with its many repeated events over a short time period might be considered more like a weather forecast than a World Cup.
Ultimately, making good decisions depends on understanding the difference between skill and luck, even if we can never fully separate the two. A prediction evaluation exercise can help us to quantify aspects of our ignorance and lead to questions about what is is that we really know.
Ultimately, the answers to these questions cannot be resolved empirically.
After this exercise, there is one thing we all know for sure. Germany are world champions, despite being looked over by the predictions. I hope you enjoyed this exercise over the past month. I’ll be doing similar exercises in the future and welcome your suggestions. Get in touch via Twitter or via my blog, details below.
.
Roger Pielke Jr. is a professor of environmental studies at the University of Colorado, where he also directs its Center for Science and technology Policy Research. He studies, teaches and writes about science, innovation, politics and sports. He has written for The New York Times, The Guardian, FiveThirtyEight, and The Wall Street Journal among many other places. He is thrilled to join Sportingintelligence as a regular contributor. Follow Roger on Twitter: @RogerPielkeJR and on his blog
.
More on this site mentioning the World Cup
Follow SPORTINGINTELLIGENCE on Twitter




